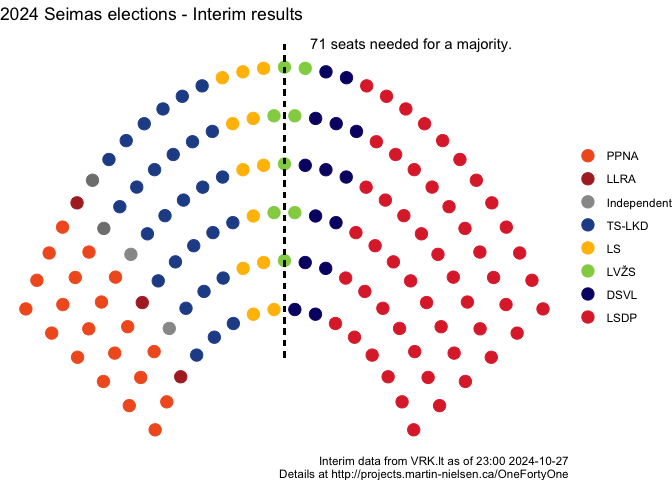
This is going to be a fairly rough and quick comparison because I didn’t get much sleep last night. It’ll take me more time and more detailed data to start to figure out what went wrong.
My calculations over-estimated TS-LKD winning power (I’ll be curious to see whether that’s where they Led or were Challenging) and underestimated LSDP power (in 2020 I think the LSDP vote may have split partially to the LSDDP).
It was overoptimistic for LVŽS and underestimated LS. (It might be worth looking at whether LP voters moved to LS when there was no LP in round 2.)
It got LLRA and LT right, and was within 1 seat for PPNA, LP and PLT.
If there is a “vote against the governing parties” bias in Lithuanian politics (and I’m starting to think there may be) then I may need to factor that into my simulation.
But let’s look at the details a bit.
In the single-member constituencies, if a candidate wins over 50% in the first round (40% beginning in 2024) they are elected. If no candidate meets this threshold, the top two candidates participate in a run-off election two weeks later.
### Build a wide multi-year table of results of past elections#linear_wide_multiyear <-NAfor (thisYear inc(2012, 2016,2020)) { first_round_results <- aggregate_round_I %>%group_by(year, constituency) %>%filter(max(perc)<0.5,year==thisYear) %>%arrange(desc(votes)) %>% dplyr::mutate(rank =row_number()) #%>%# Add a new row which contains a fake candidate for each constituency# who collects all the votes given to candidates who do not progress# to the second round## first_round_subtotals <- first_round_results %>%ungroup() %>%split(.$constituency) %>%map(~add_row( .,year = thisYear,given_name ="An",family_name ="Other",constituency =unique(.$constituency),constituency_number =unique(.$constituency_number),party ="Other",#eligible_voters = NA,votes =sum(.$votes, na.rm =TRUE),total =NA,perc =NA ) ) %>%bind_rows() %>%group_by(constituency, constituency_number) %>% dplyr::mutate(carry =if_else(rank <3, votes, 0)) %>% dplyr::mutate(carry =if_else(is.na(rank), votes -sum(carry, na.rm =TRUE), carry)) %>% dplyr::mutate(votes =if_else(is.na(rank), 0, votes)) linear_combined <-left_join( first_round_subtotals, aggregate_round_II,by =c("year","given_name", "family_name", "constituency", "constituency_number", "party", "Acronym"),suffix =c("_I", "_II") ) linear_wide <- linear_combined %>%select(-given_name,-family_name) %>%filter(carry >0) %>%pivot_wider(id_cols =c(year,constituency),names_from = rank,values_from =c(Acronym, carry, votes_II) ) %>%#dplyr::select(-party_NA, -votes_II_NA) %>% dplyr::rename(final_1 = votes_II_1, final_2 = votes_II_2) %>% dplyr::mutate(matchup =paste(Acronym_1, Acronym_2)) %>%#dplyr::mutate(Acronym_1 = factor(Acronym_1, levels = ordered_party_list_all_years, ordered = TRUE),# Acronym_2 = factor(Acronym_2, levels = ordered_party_list_all_years, ordered = TRUE)) %>% dplyr::mutate(flip =if_else((final_1 < final_2), TRUE, FALSE))if ( length(linear_wide_multiyear)==1) {# This used to test against is.na but that stopped working sometime# between 2020 and 2024 linear_wide_multiyear <- linear_wide } else { linear_wide_multiyear <-bind_rows(linear_wide_multiyear, linear_wide) }}
Part A - Vote share and Vote lead
Code
# Set the thresholds for the heuristic we'll use - it's here so I can# refer to it in the body of the text later.VoteShareThreshold <-0.4VoteGapThreshold <-0.16# But let's be quick and work from VRK summaries:First_round_results_2024_10_14_0849_cet_Rezultatai_vrk_lt <-read_excel("First round results 2024-10-14 0849 cet Rezultatai - vrk.lt.xlsx", skip =8)Multimember_results_2024_10_14_1830_cet_Rezultatai_vrk_lt <-read_excel("Multimember results 2024-10-14 1830 cet Rezultatai - vrk.lt.xlsx", sheet="data_lt",skip =11) %>%rename(Candidate="Kandidatas", "Electoral Constituency"="Apygarda", "Nominated by"="Partijos, koalicijos pavadinimas")## Work out MMP winnersmultimember_party_results <- Multimember_results_2024_10_14_1830_cet_Rezultatai_vrk_lt %>%filter(`Electoral Constituency`=="Daugiamandatė") %>%select(-`Electoral Constituency`) %>%left_join(party_names, by=c("Nominated by"="Name"))MPs_elected_first_round <- Multimember_results_2024_10_14_1830_cet_Rezultatai_vrk_lt %>%filter(`Electoral Constituency`!="Daugiamandatė") %>%select(-`Electoral Constituency`) %>%left_join(party_names, by=c("Nominated by"="Name"))## work out first round leaders# Set the thresholds for the heuristic we'll use - it's here so I can# refer to it in the body of the text later.VoteShareThreshold <-0.4VoteGapThreshold <-0.16VoteGapThreshold2024 <-0.17FirstRoundFractions_2024 <- linear_wide_multiyear %>%filter(year ==2024) %>%mutate(`Vote Share`= carry_1/(carry_1+carry_2+carry_NA),`Vote Gap`= (carry_1-carry_2)/(carry_1+carry_2+carry_NA)) %>%rename(Leader=Acronym_1, Challenger=Acronym_2)WithinThresholds_2024 <- FirstRoundFractions_2024 %>%filter(`Vote Share`<VoteShareThreshold, `Vote Gap`<VoteGapThreshold2024) LikelyElected_2024 <- FirstRoundFractions_2024 %>%filter(`Vote Share`>=VoteShareThreshold ||`Vote Gap`>=VoteGapThreshold2024) expected_winners_part_A <- LikelyElected_2024LeaderParties_2024 <- FirstRoundFractions_2024 %>%group_by(Leader) %>%tally()## Add in the first round results for 2024#for (thisYear inc(2024)) { first_round_results <- aggregate_round_I %>%group_by(year, constituency) %>%filter(max(perc)<0.4,year==thisYear) %>%arrange(desc(votes)) %>% dplyr::mutate(rank =row_number()) #%>%# Add a new row which contains a fake candidate for each constituency# who collects all the votes given to candidates who do not progress# to the second round## first_round_subtotals <- first_round_results %>%ungroup() %>%split(.$constituency) %>%map(~add_row( .,year = thisYear,given_name ="An",family_name ="Other",constituency =unique(.$constituency),constituency_number =unique(.$constituency_number),party ="Other",#eligible_voters = NA,votes =sum(.$votes, na.rm =TRUE),total =NA,perc =NA ) ) %>%bind_rows() %>%group_by(constituency) %>% dplyr::mutate(carry =if_else(rank <3, votes, 0)) %>% dplyr::mutate(carry =if_else(is.na(rank), votes -sum(carry, na.rm =TRUE), carry)) %>% dplyr::mutate(votes =if_else(is.na(rank), 0, votes)) linear_combined <- first_round_subtotals %>%rename(votes_I=votes,total_I=total,perc_I=perc) %>%mutate(votes_II=NA,total_II=NA, perc_I=NA) linear_wide <- linear_combined %>%select(-given_name,-family_name) %>%filter(carry >0) %>%pivot_wider(id_cols =c(year,constituency,constituency_number),names_from = rank,values_from =c(Acronym, carry, votes_II) ) %>%#dplyr::select(-party_NA, -votes_II_NA) %>% dplyr::rename(final_1 = votes_II_1, final_2 = votes_II_2) %>% dplyr::mutate(matchup =paste(Acronym_1, Acronym_2)) %>% dplyr::mutate(Acronym_1 =factor(Acronym_1, levels = ordered_party_list_all_years, ordered =TRUE),Acronym_2 =factor(Acronym_2, levels = ordered_party_list_all_years, ordered =TRUE)) %>% dplyr::mutate(flip =if_else((final_1 < final_2), TRUE, FALSE))# This used to test against is.na but that didn't workif (length(linear_wide_multiyear)==1) { linear_wide_multiyear <- linear_wide } else { linear_wide_multiyear <-bind_rows(linear_wide_multiyear, linear_wide) } }Part_A_Winners_2024 <- linear_wide_multiyear %>%filter(year ==2024) %>%mutate(`Vote Share`= carry_1/(carry_1+carry_2+carry_NA),`Vote Gap`= (carry_1-carry_2)/(carry_1+carry_2+carry_NA)) %>%select(constituency, constituency_number, Acronym_1, Acronym_2, matchup, `Vote Share`, `Vote Gap` ) %>%rename(Party=Acronym_1, Challenger=Acronym_2) %>%mutate(constituency_number =as.numeric(constituency_number)) %>%filter(`Vote Gap`>= VoteGapThreshold2024, `Vote Share`< VoteShareThreshold) %>%unique() %>%arrange(constituency_number) %>%relocate(constituency_number) %>%mutate(`Vote Share`=`Vote Share`*100,`Vote Gap`=`Vote Gap`*100) %>%rename("Constituency Number"= constituency_number,Constituency = constituency,"Match-up"= matchup)Part_A_Parties_2024 <- Part_A_Winners_2024 %>%group_by(Party) %>%tally()
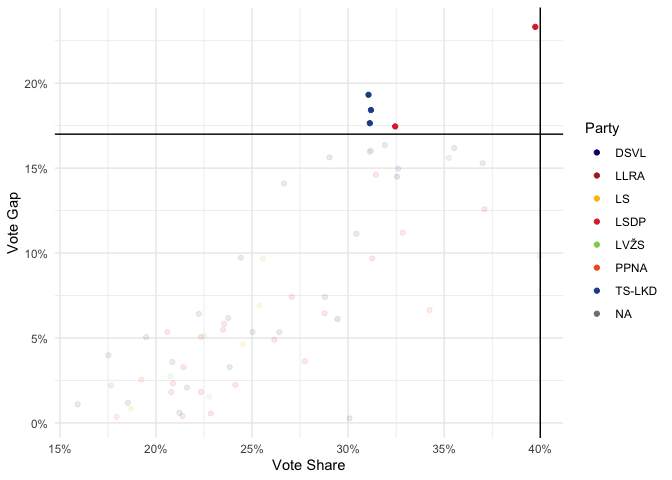
Candidates who led with more than 40% of the vote in the first round all won in the second round in 2012 and 2016, and then the law seems to have changed. But many candidates with less than 40% of the vote won in both rounds.
When I looked at the 2024 data, I chose to move the threshold up slightly, to 17%
This assigned three seats to TS-LKD and two seats to the LSDP.
Code
kable(Part_A_Winners_2024, digits=2)
Constituency Number
Constituency
Party
Challenger
Match-up
Vote Share
Vote Gap
6
Šeškinės–Šnipiškių
TS-LKD
LSDP
TS-LKD LSDP
31.19
18.42
18
Panemunės
TS-LKD
LSDP
TS-LKD LSDP
31.13
17.65
20
Centro–Žaliakalnio
TS-LKD
LS
TS-LKD LS
31.06
19.32
30
Alytaus
LSDP
TS-LKD
LSDP TS-LKD
32.45
17.46
42
Raseinių–Josvainių
LSDP
LVŽS
LSDP LVŽS
39.74
23.32
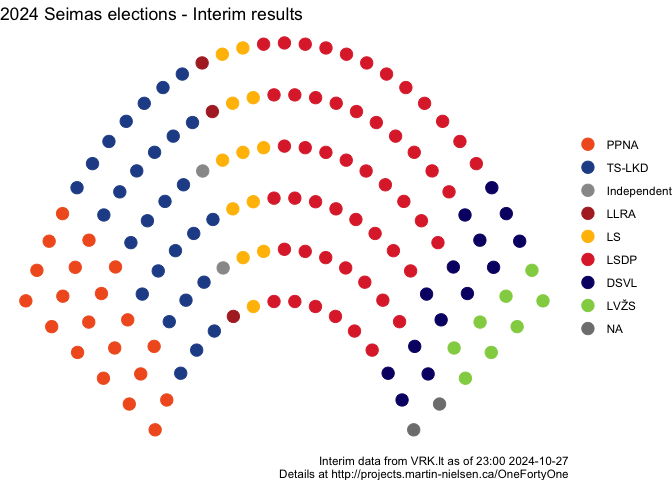
Interestingly, this approach assigned Panemunė to the TS-LKD; current VRK interim results (23:00 Vilnius time, 27 October) show the LSDP candidate (Audrius RADVILAVIČIUS) winning the second round with 52% of the vote. Note that the LSDP candidate who had a lower vote gap – but higher vote share – did win their seat, in Alytus.
Part B - Estimating outcomes based on past success rates
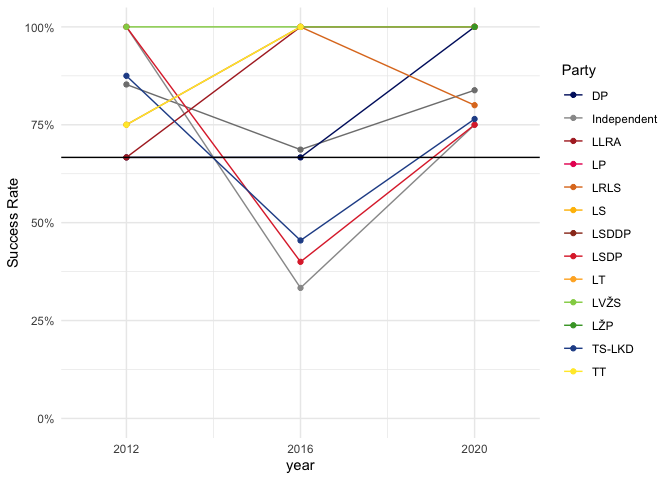
In general, candidates who placed first in the first round win the second round, but the success rates vary from year to year. I refer to the candidate who won the most votes in the first round as the Leader, and the second-placed candidate as the Challenger.
85% of first round winners won the second round in 2012
69% of first round winners won the second round in 2016
84% of first round winners won the second round in 2020
This masks wide variation among parties and between years
TS-LKD retained their lead in 87.5% times in 2012 but only 40% in 2016
We can look at the success rates of the different parties from year to year, which emphasises how unusual 2016 was compared with 2012 and 2020 (and particularly how bad it was for TS-LKD, LSDP and independent candidates). This does mask how many candidates are being considered at each point.
I made a graph which showed both those confirmed as elected and those leading in the first round in single-member constituencies, and added in the 5 seats where the vote gap is above 17%, counting them as confirmed – even Panemunės.
This is somewhat useful and suggests that these seats are uncertain, but doesn’t reflect who the challenger is for each constituency.
When we looked at success rates year to year earlier, 2016 looked very odd. A key question for 2024 is whether we think 2016 was an outlier, or whether it reflects a broader range of how Lithuanian parties perform in elections.
In the end, I treated 2016 as an outlier, and base calculations for party-by-party success rates on the data for 2012 and 2020. Looking back less than 24 hours later, I wonder if this was a mistake.
# MaximumMaxLeaderSuccess <-80# Typical (for where we have no previous data)# This is what the figure was in the past, it is now being bumped up to 2/3#AverageLeaderSuccess <- 60AverageLeaderSuccess <-2/3*100
We’ll apply a maximum of 80% and assign a typical chance of success of 66.6666667% where we don’t have earlier data. For the Liberalų sąjūdis, I treated them as a continuation of the LRLS.
The second round of the election was then simulated \(5\times 10^{4}\) times. Essentially a weighted coin was flipped for each constituency in each simulated election.
The probability of the leader winning is given by the adjusted probabilities we have calculated — if they lose, the challenger wins the seat.
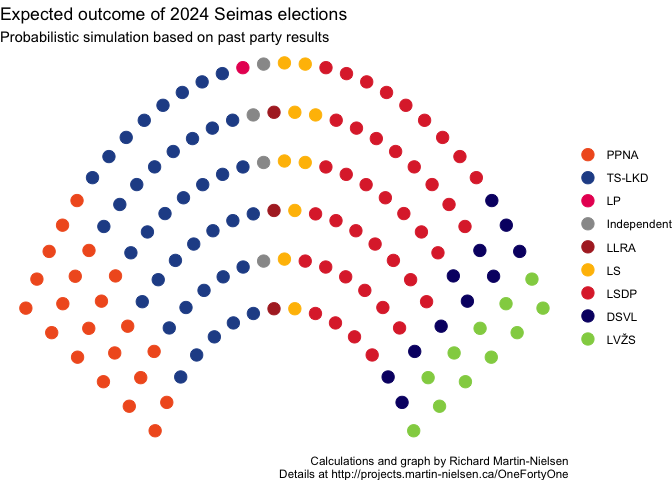
The many simulations were then compiled to see how many seats on average the party will win — the “expected” number of seats.
Monte Carlo isn’t necessary here
Because these are essentially the sum of many independent probability distributions, the calculations could be done without running the Monte Carlo.
A future project may be to rewrite this so that the model can be calculated exactly, letting me adjust the probabilities more quickly, and seeing if I can get better fit across the years (including for 2024.)
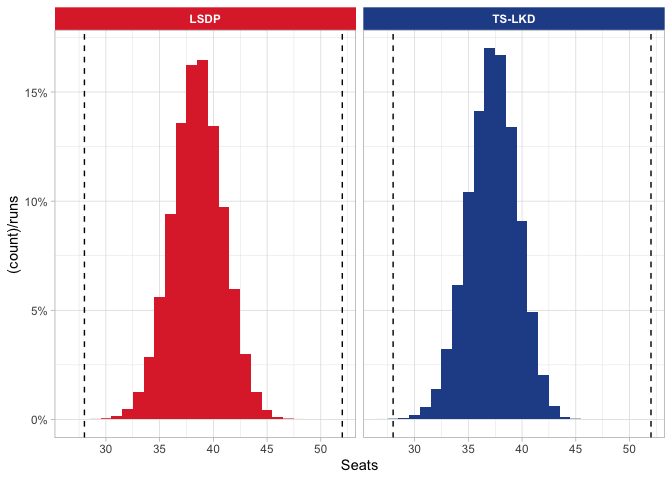
Histograms can show the distribution of the different numbers of seats for each party. The lump being further right means that the party is likely to win more seats. A narrow lump indicates that the party’s chances are limited in a tight range, usually because it is only competing for a limited number of seats in the second-round.
Having looked at all the numbers, I’m going to focus on the histograms for LSDP and TS-LKD.
These dashed lines indicate the interim result seat values for the LSDP (52) and the TS-LKD (28): clearly my tails need to be wider!
Conclusions
I was relatively confident very early this morning that my model would work about as well in 2024 as it did in 2020.
This wasn’t the case. When there are more data available (including vote counts by constituency) I’ll have a closer look to see what I may have missed.
I’m curious to look at where the expectation of a win or loss was upset by actual outcomes, and if there are things which may be correlated to that (whether it may be voter gaps between leader and challenger, or the identities of the parties involved). I’m also curious to look at seeing whether participation in the government can help predict success in elections. In this round, there were significant reversals of fortune for the LSDP, TS-LKD, and LVŽS - and the LP will no longer be represented in parliament.
I think I will try seeing if I can build a version of this code which avoids the Monte Carlo approach and can calculate expected values and distributions exactly. This may make it faster to see how the model could be tuned to be ready for 2028. And I may go back to some of my other experiments looking at constituency trends and party-specific trends. A month ago I had comparable data on three Lithuanian parliamentary elections, and soon I will have data for four, which may also help determine if 2016 was an outlier, or if 2016 is like 2024, and 2012 is like 2020.